

Wat is NoSQL! De voors en tegens
Nearshore software development: actuele ontwikkelingen: Hoe kiest u een geschikte datastore? Op zichzelf al moeilijk te verenigen eisen en een onvoorspelbare toekomst maken die keuze soms zeer complex. In het snel groeiende aanbod kan het verschijnsel Not Only SQL een interessante optie zijn.
In software-ontwikkeling bepalen allereerst de verwachte prestatie-eisen de keuze van een datastore: de geschatte belasting van het systeem, de maximale en gemiddelde aantallen gelijktijdige gebruikers, de vermoedelijke datavolumes en de duur van de periode waarin de gegevens beschikbaar moeten zijn. Een tweede stap bestaat uit een analyse van de aard en het gebruik van de gegevens en de functionaliteit van de applicatie: raadplegen de gebruikers alleen gegevens of rapporteren ze ook? Is er sprake van transacties? Worden gegevens online verwerkt?
Het programma van eisen aan het database-systeem begint nu wat meer concreet vorm te krijgen:
* Het systeem moet bijvoorbeeld meer schrijf- dan leeshandelingen kunnen verwerken (of andersom)
* Sommige of alle transacties moeten voldoen aan de ACID-criteria: Atomiciteit, Consistentie, Geïsoleerd, Duurzaamheid
* Het systeem ondersteunt al of niet een vorm van replicatie en laat een bepaald percentage van de afhandeling over aan een of meer replica’s
* Het kan nodig zijn enig mechanisme van high-availability/failover te ondersteunen
* In het geval van databases van meerdere terabytes kan het nodig zijn multi-server gegevenspartitionering te ondersteunen
Verschillende van deze geenszins uitzonderlijke eisen passen in het concept van horizontale schaalbaarheid: door de database uit te breiden naar meerdere server nodes ondersteunt het systeem grote datavolumes, meer gelijktijdige gebruikers en meer bewerkingen per seconde, terwijl er tevens ruimte is voor failover-functionaliteit. Dit in tegenstelling tot verticale schaalvergroting: het toevoegen van meer en meer hardware aan een enkele machine, zoals een upgrade van 16 naar 24 CPU’s of van 64 GB naar 128 GB RAM. In het vervolg van dit artikel richten we ons op enkele interessante aspecten van het hoe en waarom van het opschalen van een database-systeem. We zullen zien dat sommmige database-systemen daarvoor beter geschikt zijn dan andere.
Schaalbaarheid: hoezo?
De vraag is niet waarom je zou moeten starten met een reeds opgeschaald database-systeem, maar waarom je schaalbaarheid vanaf de ontwerpfase van het software-ontwikkelproces mogelijk zou willen maken. Het antwoord is simpel: in de ontwerpfase is het niet altijd mogelijk het gedrag en de belasting van een systeem te voorspellen. Door allerlei oorzaken kunnen performanceproblemen ontstaan in latere ontwikkelstadia of pas als de software al volop in gebruik is. Soms zijn de datavolumes niet nauwkeurig bepaald.
Hogere volumes kunnen de query-prestaties beïnvloeden. En soms zijn ook de aantallen gelijktijdige gebruikers niet nauwkeurig bepaald. Deze twee laatstgenoemde verschijnselen kunnen zich ook gecombineerd voordoen. In ieder van deze gevallen moet het systeem geheel of gedeeltelijk terug naar de tekentafel. Pas na de bouw en uitrol van de aangepaste versie zal het systeem voldoen aan de hogere prestatie-eisen.
Sommigen beschouwen het inbouwen van optionele horizontale schaalbaarheid als voortijdige optimalisatie, vooral als niet duidelijk is of het nodig is of niet. Het is echter een feit dat deze voortijdige optimalisatie geen kosten met zich meebrengt. Het openhouden van de mogelijkheid vereist geen enkele wijziging in de implementatie van het project. Doet de behoefte aan schaalbaarheid zich ooit voor, dan is er op ieder gewenst moment volledig transparant in te voorzien, terwijl het systeem initieel kleinschalig in gebruik is te nemen.
De ontwerpbeslissing om software horizontaal schaalbaar te maken kan neerkomen op het selecteren van het juiste database-systeem en het maken van enkele technische ontwerpkeuzes rondom het organiseren van gegevens in de opslag. Het opschalen is op meerdere manieren te realiseren, afhankelijk van de noodzaak:
* Replicatie naar een of meerdere online nodes in een cluster van databases
* Gegevenspartitionering
* Replicatie naar een of meerdere alleen-lezen en stand-by kopieën
Wat is NoSQL precies?
De term NoSQL staat voor Not Only SQL en wordt gebruikt voor een nieuw en steeds populairder type database-systemen die in meerdere opzichten afwijken van hun klassieke relationele tegenhangers. Het concept NoSQL is het eenvoudigst uiteen te zetten met behulp van het CAP-theorema. In dit theorema kan een database-systeem altijd een van de volgende eigenschappen hebben:
– Consistency (consistentie): alle nodes in een cluster bevatten op ieder moment dezelfde data
– Availability (beschikbaarheid): aan elk verzoek wordt gegarandeerd voldaan, ook als delen van de cluster offline zijn
– Partition tolerance (partitietolerantie): een netwerkstoring tussen twee of meer nodes in een cluster of tussen clusters leidt niet tot downtime voor gebruikers. De andere nodes of clusters blijven online en zijn in staat alle verzoeken af te handelen.
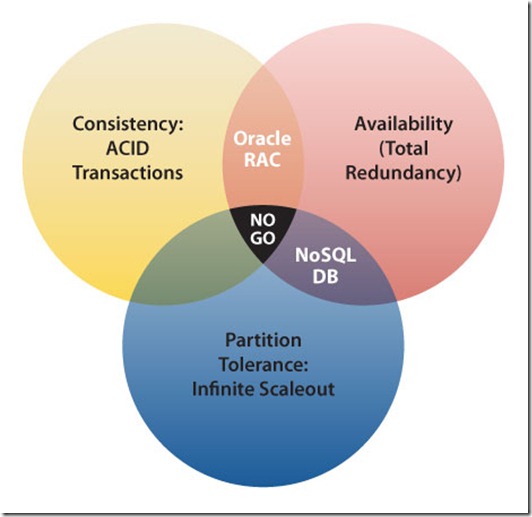
De meeste NoSQL-systemen passen in de twee categorieën Availability en Partition tolerance. Met de eigenschap Consistency is het anders gesteld: in plaats van consistentie biedt NoSQL eventual consistency ofwel uiteindelijke consistentie. Database-systemen die men beschouwt als consistent voldoen vaak aan het eerdergenoemde ACID-principe: Atomiciteit, Consistentie, GeÏsoleerd, Duurzaamheid. Uiteindelijk consistente database-systemen zijn gebaseerd op het BASE-principe:
– Basically Available: het systeem is 24/7 beschikbaar
– Soft State: het is niet noodzakelijk dat het systeem voortdurend op ieder tijdstip consistent is: niet alle nodes in een cluster bevatten op ieder moment dezelfde data
– Eventually Consistent (uiteindelijk consistent): ook al is het systeem of de cluster niet op ieder tijdstip consistent, er is de garantie dat het systeem of de cluster op een bepaald tijdstip consistent zal zijn ofwel dat alle nodes dezelfde data zullen bevatten
Bijzondere ontwerpconcepten die zijn te vinden in onder meer NoSQL systemen zijn:
* Schema-loos: de ‘tabellen’ hebben geen vooraf gedefinieerd schema. Het aantal velden kan van record tot record variëren en zowel de content als de semantiek worden bepaald door applicaties.
* Shared nothing-architectuur: elke node in een cluster is onafhankelijk van de andere en zelfvoorzienend. Ook bekend als master-less design.
* Elasticiteit: zowel opslag- als servercapaciteit is on-the-fly en zonder downtime uit te breiden door het toevoegen van servers. Een nieuwe node komt online, wordt gesynchroniseerd met de cluster en begint verzoeken af te handelen.
* Sharding: de ruimte voor opslag wordt niet beschouwd als een geheel, maar records worden gepartitioneerd in onderdelen. Dat zijn shards of scherven. Een shard is meestal klein genoeg voor een enkele server, hoewel shards veelal worden gerepliceerd. Sharding kan ofwel automatisch plaatsvinden doordat een shard zichzelf splitst zodra deze te groot wordt, ofwel worden ondersteund door een applicatie die ieder record een partitie-identifier toewijst.
* BASE binnen een cluster: bij NoSQL databases gaat het om prestaties en beschikbaarheid. Dit vereist een zodanige prioritering van de onderdelen van het CAP-theorema dat strikte ACID-transacties binnen een cluster niet plausibel zijn.
* ACID binnen een node: hoewel ACID niet is gewaarborgd in een cluster als geheel, kan dat wel gelden voor afzonderlijk nodes. Dit kan een aantal voordelen bieden.
Waarom is NoSQL überhaupt een optie?

De NoSQL-familie van database-systemen is door een reeks gemeenschappelijke kenmerken een aantrekkelijke optie voor het ontwikkelen van software in alle mogelijke maten, van eenvoudige backoffice-applicaties tot grootschalige online transaction processing-systemen.
Over het algemeen zijn er goede redenen om te kiezen voor een NoSQL oplossing:
– Ontworpen met het oog op schaalvergroting
– Ondersteuning van MapReduce queries met een verbeterde parallelle uitvoering van queries
– Ingebouwde en gemakkelijk te configureren failover/fouttoleranties
– Can do analytics
– Flexibiliteit dankzij schema-loze entiteiten
– Snelle ontwikkeling omdat modellering niet langer noodzakelijk is
– Big Data is geen probleem
– Ongestructureerde gegevens zijn prima op te slaan
Hoe werkt NoSQL?
Zodra het criterium van ACID-compliancy binnen een cluster vervalt, ontstaan er nieuwe mogelijkheden voor horizontale schaalbaarheid. Dit geldt vooral voor schrijfhandelingen, omdat cross-cluster locks en transactionele synchronisaties niet langer noodzakelijk zijn.
In NoSQL databases is schaalbaarheid op verschillende manieren te realiseren. Een database is 1 op 1 te repliceren naar meerdere nodes met behulp van de al eerder genoemde shared nothing-architectuur, tevens bekend als master-less design. Dit is vooral nuttig bij de toepassing van load balancing op de toegang tot de datastore om de druk op een bepaalde set instantie te verlagen.
Daarnaast ondersteunen sommige NoSQL producten multi-site replicatie. Dit houdt in dat clusters in verschillende datacenters met elkaar kunnen synchroniseren. Dergelijke functionaliteit is handig als een applicatie of een website wordt gedistribueerd via een Content Delivery Network om verschillende geografische gebieden snel toegang en een hoge beschikbaarheid te bieden.
Een andere schaalbaarheidsoptie staat bekend als sharding of databasepartitionering, maar de meest gebruikte naam is shard: een database die ontstaat uit de mogelijkheden van een enkele node wordt gesplitst in partities of shards die naar meerdere nodes worden gedistribueerd. Deze shards zijn op hun beurt afzonderlijk te repliceren.
Hoe kies ik een NoSQL-database?
De selectie van een NoSQL-database hangt af van verschillende factoren die niet per se aan schaalbaarheid zijn gerelateerd:
– De verhouding tussen lees- en schrijfhandelingen: sommige systemen zijn beter geschikt voor meer schrijfhandelingen, andere juist voor meer leeshandelingen
– De complexiteit van het datamodel
– De eisen aan de infrastructuur: sommige NoSQL-systemen vereisen additionele control servers voor het configureren van modes voor hoge beschikbaarheid en replicatie.
– De vraag of een tijdelijke caching-layer volstaat of dat er een volledige persistentie layer nodig is
– De vraag welke types gegevens worden opgeslagen: documenten, ongestructureerde data, hiërarchische gegevens, gegevens die kunnen worden gemodelleerd met behulp van graph theory elementen of met behulp van XML
Het aantal NoSQL-producten groeit snel. Daardoor kan het lastig zijn een keuze uitsluitend te baseren op vooraf geformuleerde eisen. Er zijn vele vergelijkbare oplossingen en de verschillen zijn soms subtiel. Alle details verdienen zorgvuldige aandacht – van de API en de beschikbaarheid van support tot en met de kenmerken van de community. NoSQL data stores zijn in te delen in de volgende categorieën:
Key/value stores
Deze databases maken efficiënte data-opslag mogelijk. In vergelijking met meer geavanceerde databases zijn ze zeer beperkt omdat ze slechts op een manier toegang tot de data (value) bieden. Andere wegen vereisen extern beheer, bijvoorbeeld via Lucene of via een index die door de applicatie wordt beheerd.
Voorbeelden: Riak, Redis, Memcached
BigTable databases
Deze databases zijn ook bekend als record-georiënteerd, databases in tabelvorm of als wide-column stores. De term BigTable is populair geworden door Googles BigTable-implementatie. Net als relationele databases bestaat een Big Table database uit meerdere tabellen, die ieder een set aan te roepen rijen bevatten. Elke rij bestaat uit een reeks waarden die zijn te beschouwen als kolommen.
Voorbeelden: Azure Tafels, HBase, Cassandra
Document databases
Deze databases zijn ook wel bekend als document-georiënteerde databases. Ze zijn ontwikkeld voor de optimale opslag van en toegang tot documenten, als tegengesteld aan een structuur van rijen of records. Document databases zijn schemaloos.
Voorbeelden: CouchDB, MongoDB, Terrastore
Grafische databases
In deze databases worden de gegevens opgeslagen in grafiekachtige structuren, in plaats van in lineaire lijsten of in key/valueparen. Ze zijn bijzonder geschikt voor sociale netwerken en bieden een natuurlijk model voor de relaties tussen de gebruikers.
Voorbeelden: Neo4j, BrightstarDB, GraphBase
Zijn er ook nadelen aan NoSQL?
Hoewel NoSQL-systemen in allerlei gebruiksscenario’s fungeren als nuttige of zelfs aangewezen oplossingen voor data-opslag, zijn ze verre van perfect.
Prestaties en schaalbaarheid vereisen investeringen en dus kosten. De ontwikkelaars van NoSQL-systemen moesten bezuinigen op verschillende eigenschappen en functionaliteiten. De meeste van deze oplossingen komen zonder of met beperkte managementsoftware zoals Microsoft SQL Server Management Studio, of pgAdmin PostgreSQL’s. Een goed deel van de configuratie moet handmatig met behulp van configuratiebestanden worden gedaan.
Een ander nadeel is dat sommige van de NoSQL-oplossingen mogelijk nog niet rijp zijn voor productie. Ze bestaan, ze worden gebruikt door enkele individuen of bedrijven, maar ze zijn nog niet getest en gebenchmarked voor de volle breedte aan gebruiksscenario’s.
De user base voor NoSQL oplossingen is nog te beperkt om snel relevante en betrouwbare informatie te vinden. Een performance benchmark voor een bepaalde NoSQL-engine is vast wel te vinden, maar die is waarschijnlijk niet van toepassing op alle use cases. Het testen en benchmarken van een oplossing voor specifiek gebruik zou verplicht moeten zijn.
Conclusie met betrekking tot NoSQL
Alle nadelen daargelaten: vergeleken met de grote groep relationele databasemanagement-systemen is de NoSQL-familie van database-systemen een nieuwkomer. De producten verdienen de aandacht van ieder die op zoek is naar een database-systeem of een caching-engine voor een applicatie.